Дубликаты страниц
05.05.2021
 Дубль страницы – это еще одна копия страницы сайта, аналогичная по содержанию и наполнению. Выделяют два вида дублей:
Дубль страницы – это еще одна копия страницы сайта, аналогичная по содержанию и наполнению. Выделяют два вида дублей:
- Полный дубликат страницы – когда содержимое полностью идентично;
- Частичный дубликат – когда наполнение страницы по большей степени одинаковое, но имеются отдельные различные элементы.
Почему дубли страниц плохо влияют на ранжирование сайта?
Поисковые системы воспринимают эти страницы, как отдельные страницы сайта, поэтому их наполнение из-за дублирования информации перестает быть уникальным. Кроме того, понижается ссылочный вес страницы, если она имеет дубль. Небольшое количество дублированных страниц может не стать большой проблемой, однако если их более 50% - вам срочно нужно исправлять ситуацию.
Откуда берутся дубли?
Самая распространенная причина – это генерация дублей страниц системой управления из-за неправильных настроек. Самый известный пример – CMS Joomla, с проблемой дублей на ней приходится сталкиваться чуть ли не на каждом сайте.
Частичные дубли часто встречаются на сайтах интернет-магазинов:
- Они могут появляться на страницах пагинации, если те содержат одинаковый текст, изменяя лишь товары;
- Неправильные настройки фильтра по каталогу могут порождать частичные и полные дубли;
- Страницы карточек товаров могут стать дубликатами, если товар, к примеру, отличается лишь цветом или размером (для таких товаров нужно делать одну карточку с указанием всех характеристик).
Как найти дубли страниц?
Есть несколько способов поиска дубликатов страниц, каждый из которых может дать разные результаты.
1. Некоторые распространенные варианты дублей можно проверить вручную.
- Настроено ли главное зеркало сайта (доступен ли он с www и без www);
- Имеются ли нечеткие дубли со / и без / на конце url;
- Наличие дублей с index.html, index.asp, index.php в конце url;
- Доступность страницы с буквами как в нижнем, так и в верхнем регистре, также порождает дубли.
2. Проанализировать страницы, проиндексированные поисковыми системами.
Для этого в Google достаточно ввести запрос site:mysite.com - он покажет страницы общего индекса, то есть все, что поисковик успел проиндексировать на сайте.
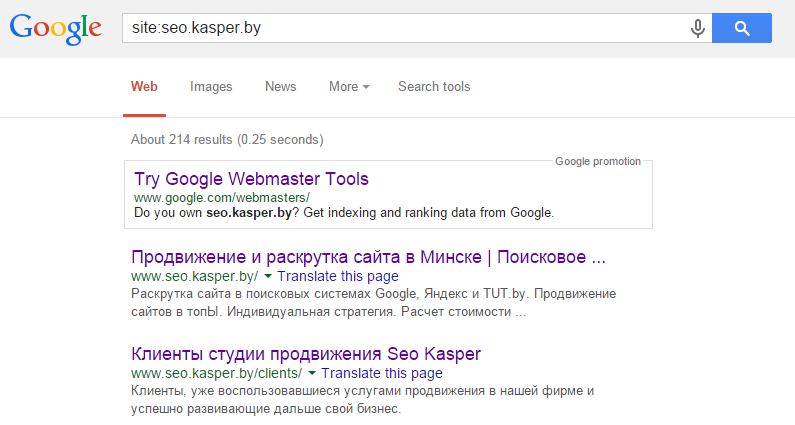
3. Поиск по фрагменту текста
Вбивая в поиск длинные фрагменты текста, можно найти места, где он повторяется (а заодно и сайты, которые скопировали ваш текст). Но здесь есть два минуса: метод подходит, если на сайте мало страниц, и то, что поисковая система может анализировать запрос до определенной длины.
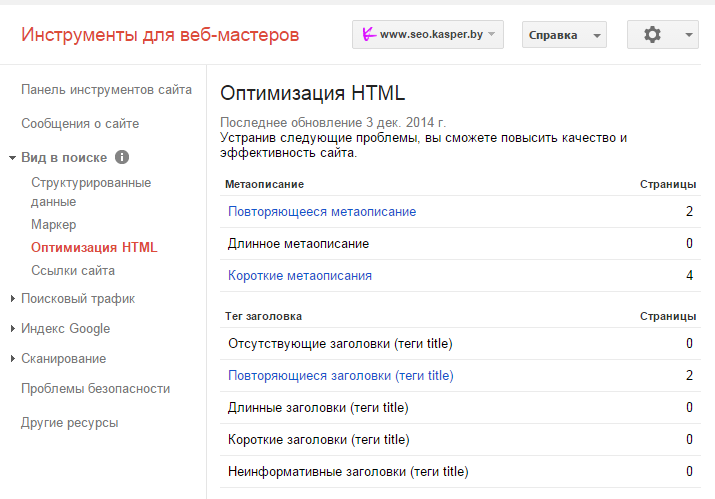
4. Заглянуть в панель вебмастера Google
В разделе «Вид в поиске» находим вкладку «оптимизация HTML» и ищем значение поля «Повторяющиеся метаописания» и «Повторяющиеся заголовки». Нажав на них, можно увидеть список всех страниц с повторяющимися тегами title и description и сами заголовки и описания.
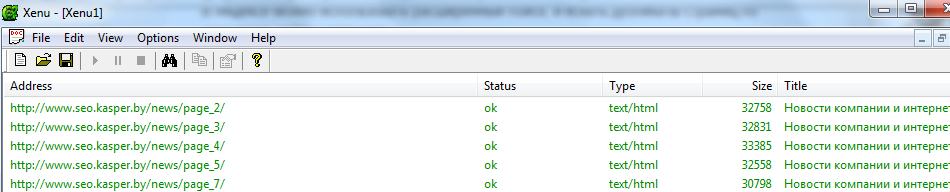
5. Воспользоваться программой Xenu`s Link Sleuth
Программа распространяется бесплатно и способна определить url всех страниц сайта, включая скрипты и картинки, а также внешние ссылки. Кроме дубликатов в ней удобно искать битые ссылки – страницы, которые возвращают код 404.
Как устранить дубли страниц?
Для этого существует 4 действенных способа, самыми жесткими из которых. По нашему мнению, являются первые два.
1. Ручное удаление
Это можно сделать на небольших сайтах, хорошенько разобравшись в своей системе управления и сделав правильные настройки, чтобы предотвратить последующее появление дубликатов страниц.
2. Настройка 301 редиректа
301 редирект – это постоянное перенаправление пользователей с одной страницы на другую, что приводит к их склеиванию. Он позволяет передать странице до 99% ссылочного веса, как внутреннего, так и внешнего.
По поводу использования 301 редиректа написаны целые мануалы. Поэтому здесь мы вкратце приведем самые нужные для устранения дублей. Настраивается он либо через файл .htaccess в корневой директории сайта, либо через программный код.
Чтобы настроить главное зеркало, необходимо прописать следующий код:
1 - для редиректа с www на без www
RewriteCond %{HTTP_HOST} ^www.site.com$ [NC]
|
RewriteRule ^(.*)$ http://site.com/$1 [R=301,L]
|
2 - для редиректа с без www на с www
RewriteCond %{HTTP_HOST} ^site.com$ [NC]
|
RewriteRule ^(.*)$ http://www.site.com/$1 [R=301,L]
|
Чтобы склеить нечеткие дубли со / и без него, воспользуйтесь кодом:
1 - убрать слэш
RewriteCond %{HTTP_HOST} (.*)
|
RewriteCond %{REQUEST_URI} /$ [NC]
|
RewriteRule ^(.*)(/)$ $1 [L,R=301]
|
2 - добавить слэш
RewriteCond %{REQUEST_FILENAME} !-f
|
RewriteCond %{REQUEST_URI} !(.*)/$
|
RewriteRule ^(.*[^/])$ $1/ [L,R=301]
|
Постраничный редирект выглядит так:
Redirect 301 /oldpage.html http://www.site.com/newpage.html
|
Для формирования более сложных редиректов потребуется воспользоваться правилами. Существуют специальные сервисы, где можно сгенерировать код для настройки редиректа по определенному шаблону:
3. Использовать Rel=”Canonical”
Этот вариант лучше использовать в случае частичных дублей, так как неканоническая страница при этом не удаляется физически с сайта и доступна пользователям.
Для того, чтобы настроить канонические url , в коде страниц в блоке head прописывается ссылка:
«link rel="canonical" href="http://site.com/kopiya"/»
4. Настройка Robots.txt
Также действенный способ, но удалить уже проиндексированные дубликаты таким образом будет сложно.
С помощью директивы Disallow указываются все адреса и их типы, на которые роботам поисковых систем не стоит заходить для индексации. Например:
User-agent: Yandex
Disallow: /index*
- говорит о том, что поисковому боту Яндекс не стоит заходить на страницы, url которых содержит index.
Найти и устранить все дубликаты – основная задача на первых этапах продвижения сайта, иначе можно взяться просто не за те страницы, и долго искать проблему.


















